Las 5 Vs que caracterizan el concepto de Big Data.
Existen muchas definiciones sobre Big Data, que van desde la definición de Tim Kraska en la que considera el Big Data como la clase de datos sobre los que la actual tecnología en aplicación no es capaz de obtener en coste, tiempo y calidad respuestas a la explotación de los mismos; pasando por la definición del McKinsey Global Institute donde se refiere al Big Data como el conjunto de datos cuyo tamaño excede las capacidades de las actuales aplicaciones de bases de datos para capturar, almacenar, gestionar y analizar los mismos; hasta llegar a la de IDC que incide en la obtención de valor de los datos al ampliar el concepto de Big Data al conjunto de nuevas tecnologías y arquitecturas diseñadas para la obtención de valor de grandes volúmenes y variedad de datos de una forma rápida, facilitando su captura, procesamiento y análisis. Tal vez esta última sea la que mejor represente el concepto de Big Data al poner de manifiesto tecnologías y datos para la obtención de valor, caracterizando dichos datos por su Volumen, Variedad y Velocidad de generación. Las tres (3) V por las que académicamente se ha venido caracterizando al Big Data.
Otro aspecto importante que nos lleva a caracterizar hoy en día el Big Data es su estado de madurez o valor que actualmente representa. En este sentido la consultora Gartner colocaba en Julio de 2012 al Big Data, dentro de su famosa representación del ciclo por el que pasa toda tecnología emergente, dejando la fase de “technology trigger” y pasando a la de “peak of inflated expectations”, como se observa en la siguiente figura.
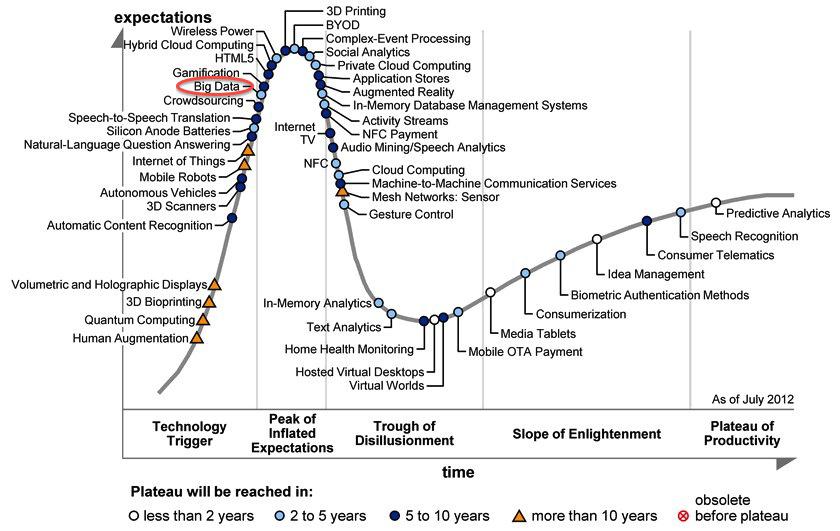
Gartner’s Hype Cycle of emerging technologies
La rapidez con que este ciclo se cubra está sujeta, fundamentalmente, a la capacidad de transmitir al potencial usuario el verdadero alcance del Big Data, con sus actuales ventajas e inconvenientes, huyendo de posiciones “inflacionistas”, que generen erróneas o vagas expectativas. No es el objeto de esta primera página del blog el entrar en estas valoraciones, que se irán cubriendo en próximos artículos. Sin embargo si cabe mencionar las iniciativas que a nivel de servicio de consultoría se están llevando a cabo en la adaptación o migración, principalmente en grandes empresas, de la explotación de sus datos a estas nuevas tecnologías del Big Data, y del impacto que pueden suponer los servicios de cloud computing para la explotación de datos para las pequeñas y medianas empresas.
Como hemos indicado anteriormente desde el punto de vista académico el concepto de Big Data se ha venido definiendo y caracterizándolo en base a tres dimensiones Volumen, Variedad y Velocidad.
La dimensión de Volumen es quizás la característica más asociada al concepto de Big Data. Las estimaciones de aumento de datos generados indican un crecimiento sin precedentes, debido a las redes sociales y a la movilidad que facilitan las redes inalámbricas y la telefonía móvil. Este incremento de datos determina un cambio de escala pasando de terabytes a petabytes y zetabytes de información, dificultando su almacenamiento y análisis. Sin embargo mucha de esta información según el tipo de utilización, puede pasar a tener un ciclo de vida de su valor muy corto, pasando a ser obsoleta de forma muy rápida. Este tipo de apreciación enlaza con la dimensión de Velocidad.
La Velocidad con que los datos son creados ha aumentado de forma considerablemente, requiriendo una respuesta adecuada a su procesamiento y análisis. Esta velocidad de respuesta es requerida para hacer frente a la obsolescencia de los datos debido a su rápida capacidad de generación, haciendo obsoleto lo que instantes antes era válido; de ahí que el procesamiento distribuido y paralelo sea unas de las tecnologías que soporten el concepto de Big Data. Por otra parte la necesidad de un analista de datos que sepa identificar para cada aplicación los datos cuyo ciclo de vida sea muy corto de los de un ciclo de vida mayor, se determina como fundamental a la hora de rentabilizar y optimizar el de los uso adecuado de los mismos aumentando la precisión y calidad de los resultados.
La Variedad en Big Data se basa en la diversidad de los tipos de datos y de sus diferentes fuentes de obtención de los mismos. Así, los tipos de datos podrán ser estructurados, semi-estructurados o desestructurados, y sus fuentes podrán provenir de text and imagen files, web data, tweets, sensor data, audio, video, click streams, log files, etc. Esta variedad determina la riqueza que en sí conlleva el concepto de Big Data. Sin embargo esta potencial riqueza aumenta el grado complejidad tanto en su almacenamiento como en su procesamiento y análisis.
Una de las características asociada a la calidad de los datos es la Veracidad de los mismos. La veracidad puede entenderse como el grado de confianza que se establece sobre los datos a utilizar. Dentro de la caracterización del Big Data la Veracidad determina su cuarta dimensión, y es de gran importancia para un analista de datos, ya que la veracidad de los mismos determinará la calidad de los resultados y la confianza en los mismos. Por lo tanto un alto volumen de información que crece a velocidad muy rápida y basada en datos estructurados y desestructurados y provenientes de una gran variedad fuentes, hacen inevitable dudar del grado de veracidad de los mismos. Por ello, dependiendo de la aplicación que se les dé, su veracidad puede ser imprescindible o convertirse en un acto de confianza sin llegar a ser vital
Desde el punto de vista de la recolección y explotación, la dimensión Valor representa el aspecto más relevante del Big Data. Actualmente el valor marginal de los datos se representa mediante la siguiente gráfica. En dicha gráfica se observa que a medida que aumenta el volumen y complejidad de los datos, su valor marginal disminuye considerablemente, debido a su dificultad de explotación.

Valor marginal de los datos
El facilitar la explotación de los datos para obtención de valor sigue siendo el objetivo fundamental del Business Intelligence y ahora de las tecnologías del Big Data. El aumentar el valor marginal de los datos es uno de los retos actuales desde el punto de vista de la tecnología, del analista, y finalmente del gestor en la mejora de la toma de decisiones, de una forma rápida, inmediata y precisa adelantándose a la competencia. Por lo que la evolución de las dimensiones del Big Data pasa por una interpretación academicista de tres dimensiones (volumen, variedad y velocidad), a una visión del analista donde la veracidad de los datos se presenta como una dimensión fundamental cara a la calidad de los resultados, hasta la visión del gestor donde la interpretación del valor se hace básica cara a la toma de decisiones.
Finalmente indicar que las redes sociales, junto a la inmediatez de las redes inalámbricas y la telefonía móvil, los nuevos servicios de almacenamiento en la nube, etc, han propiciado, que cada vez se genere un mayor volumen de datos, y de forma muy rápida, provenientes de pocos o muchas fuentes de información, cuya veracidad es difícil de constatar, y cuyo tiempo de validez puede no ser muy grande. Ante este tipo de escenarios, constatados por la experiencia de las empresas basadas en internet, el llegar a verlos, no como una dificultad, sino como una ventaja competitiva es uno de los retos actuales de la implantación de la tecnología asociada al concepto de Big Data.
Comentarios